
La quantité de documents gérés dans le cloud Microsoft n’a cessé de grandir au fur et à mesure de son adoption par les entreprises de toutes tailles. En conséquence, les processus de gestion et traitement des documents se sont également retrouvés contenus dans le cloud, sans nécessairement être facilités ou adaptés à ce volume désormais dématérialisé.
Dans le cadre du Projet Cortex, Microsoft a dévoilé en 2022 un produit dont l’objectif est d’aider et automatiser le traitement de documents types à l’intérieur de ses applications documentaires Microsoft 365 : Microsoft Syntex.
Synthétiser Microsoft Syntex
Pour paraphraser Jeff Teper lors de la présentation de Microsoft Syntex, ce nouvel outil est un nouvel éventail de possibilités qui introduisent la gestion de contenu par l’IA dans le flux de travail.

Malgré le fait d’être une phrase riche en mots-clefs, elle ne défini pas précisément le rôle que Microsoft Syntex peut prendre dans le cadre du traitement des documents. Le reste de la présentation rentre plus en détail, mais nous allons dans cet article passer en revue la fonctionnalité la plus pertinente.
Concrètement, Microsoft Syntex est un flux d’automatisation de lecture et classification des documents dans SharePoint, et intègre en compagnon des fonctionnalités de recherche ainsi que d’autres intégrations avec l’écosystème M365, tel que Power Automate.
Le but principal de Microsoft Syntex est de lire un document, en extraire des données pertinentes, les associer au document dans SharePoint et finalement classer le document en se basant sur la typologie des informations extraites. De cette manière, le volume de documents traité de cette manière devient trivial, laissant aux utilisateurs plus de temps pour traiter les documents dans leur globalité et ouvrant la porte à d’autres avenues d’automatisation.
À chaque document, un Modèle
La grande majorité des documents générés en large volume suivent un modèle, un type qui permet de trier son contenu d’une manière logique et pertinente. Mais même à l’intérieur d’un même type de document, par exemple des factures ou des devis, il existe autant de variété que d’éditeurs de ces documents. Les reçus de magasins transmettent largement tous les mêmes informations, mais ceux produits par une chaîne ne seront jamais identiques à ceux d’une autre, malgré le fait que les informations sont largement les mêmes. Cette variété de forme, mais pas de fond est un exemple type de document dont le traitement manuel est fastidieux, voire pénible pour l’utilisateur. Il en va de même pour les documents à rallonge dans laquelle l’information est peut-être uniforme, mais extrêmement dense et intellectuellement pauvre, telle que des codes de produits, des numéros de lots mélangeant des chiffres et des lettres (sans le charme de Laurent Romejko !).
Microsoft Syntex se base sur un système de modèles paramétrés en amont par un utilisateur (qui peut être un administrateur ou un utilisateur final, en fonction des restrictions imposées par le service informatique de votre organisation) et entraîné sur des documents type d’exemple et de contre-exemple et qui se renforcera à travers son utilisation. Ce modèle est ensuite appliqué à une ou plusieurs bibliothèques de document et Microsoft Syntex appliquera les modifications auxquelles il a été entraîné.
Chaque Modèle est composé de deux parties :
- Un Classifieur
- Un Extracteur
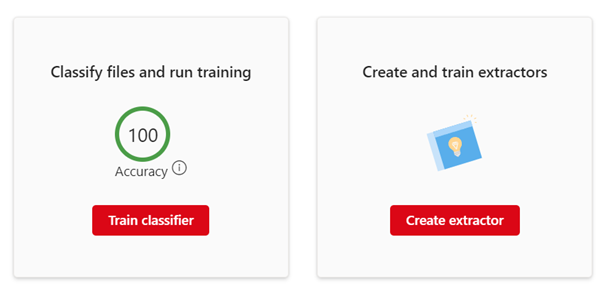
En parallèle, un module de Labels de Sensibilité et de Rétention permet de joindre Microsoft Syntex aux politiques de Compliance existantes dans votre écosystème.
Le Classifieur est le module qui va déterminer si un document appartient ou non à un type prédéfini. Par exemple, dans une bibliothèque qui a vocation à contenir des devis, des contrats et des factures, c’est lui qui aura la charge de définir si un document appartient à l’une de ces catégories.
Le Classifieur est entraîné en 3 étapes :
- Les exemples
- Les explications
- Les tests
1ère étape : Les Exemple
L’entraînement par Exemple consiste à « nourrir » au modèle des documents types qu’il sera amené à traiter, tant positifs que négatifs. Les documents d’exemples sont lus par le modèle, et les informations qu’ils remontent sont ensuite déclarées par le créateur du modèle de manière à former une base de connaissance. La force de cette étape est dans le fait que Microsoft Syntex n’a pas nécessairement besoin que la forme du document soit respectée d’un document type à un autre.

Il est possible de mélanger plusieurs formats de documents, à partir du moment où les informations contenues dans ces documents sont les mêmes pour l’identifier. Cela peut être une formulation dans le document, un en-tête, une série de chiffres de taille spécifique, par exemple. Le plus de documents sont ainsi manuellement fournis au Modèle, le plus apte il sera à déterminer si un document est conforme au type qu’il recherche.
2ème étape : Les Explications
Les Explications consistent à formuler des requêtes précises dans le document pour identifier des zones ou des données qui identifient plus spécifiquement le type de document.
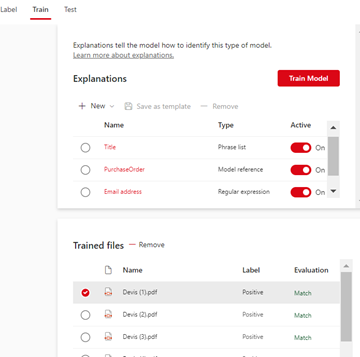
Ces requêtes permettent une grande flexibilité pour analyser des documents plus sémantiquement complexes : analyse par zone dans le document, expressions régulières, formules avant après certains mots clefs, fin début de paragraphe…
3ème étape : Les Tests
Finalement, l’étape de Test consiste à confronter le modèle à des documents qu’il n’a pas utilisé pour s’entraîner pour tester son comportement et le cas échéant réintroduire les faux positifs ou négatifs dans l’entraînement pour affiner son analyse. Ce cycle de vie d’entraînement permet aussi aux Modèles d’évoluer à travers le temps et les besoins de classement de votre organisation.
Les Extracteurs, comme leur nom l’indique sont présents pour extraire des données depuis ces documents et les appliquer en métadonnées dans la bibliothèque, ce qui permet par exemple de les automatiser avec Power Automate, de créer des vues et des filtres basés sur les données extraites automatiquement, les exporter vers des tableaux etc.
Chaque Extracteur se charge d’une donnée et s’entraîne de la même manière que le Classifieur, avec les exemples, les explications et les tests. Lors de l’entraînement, le Modèle présente la donnée qu’il détecte afin de d’aider l’utilisateur à raffiner la manière de l’extraire et son format.

Dans quel but utiliser Microsoft Syntex ?
Dans l’absolu, Microsoft Syntex est comme un compagnon de lecture de document qui va jeter un œil sur chaque document, extraire les informations qu’on lui a dit être pertinentes et va les mettre dans les casiers qui y correspondent, le tout dans un temps imbattable. Comme tout autre collaborateur, il dépend de la formation qu’on lui a donnée pour être efficace, mais une fois qu’il a prit ses marques, il sera vite indispensable tant dans ses fonctions que dans le temps qu’il fait gagner à l’organisation.
La force de Microsoft Syntex est directement proportionnelle à la quantité d’information qu’on lui demande de traiter. A une époque où la virtualisation des données est inévitable et que même les sources papiers commencent à être mises en question, chaque instant passé à faire manuellement ce qui peut être automatisé est un instant qui pourrait être réinvesti dans les processus qui ne sont pas automatisables.
Grâce à l’automatisation de l’extraction d’information, avec l’amélioration de la recherche de document qui découle de l’indexation de ces mêmes données, Microsoft Syntex propose de libérer le potentiel des utilisateurs pour des tâches plus valorisantes tant pour l’utilisateur que son organisation.
En combinaison avec les autres outils d’automatisation de Microsoft 365 tels que Power Automate, Power Apps, et même des outils tiers qui se basent ne serait-ce que partiellement sur les métadonnées des documents comme Nintex, Microsoft Syntex propose un moyen simple et accessible d’optimiser la lecture de documents en masse à travers votre cloud M365.
Microsoft Syntex est une technologie encore jeune dans l’univers Microsoft 365, mais Microsoft est clairement investi dans le développement de l’IA pour soutenir son écosystème et les utilisateurs qui en font usage.
Vous souhaitez en savoir davantage à propos de Microsoft Syntex ? N’hésitez pas à nous contacter dès aujourd’hui !